分布式配置管理
配置的集中管理:采用consul的KV,将所有微服务的application.properties中的配置内容存入consul。
配置的动态管理:采用archaius,将consul上的配置信息读到spring的PropertySource和archaius的PollResult中,当修改了配置信息后,经常改变的值通过DynamicFactory来获取,不经常改变的值可以通过其他方式获取. 大部分情况下,修改了consul上的配置信息后,相应的项目不需要重启,也会读到最新的值。
#1. StatsD - metrics data collecting
#2. Graphite - metrics data graphing and storage
在Kubernetes中,Secret对象类型主要目的是保存一些私密数据,比如密码, tokens, ssh keys等信息。将这些信息放在Secret对象中比直接放在pod或docker image中更安全,也更方便使用。
创建Secrets对象的方式有两种,一种是用户手动创建,另一种是集群自动创建。
一个已经创建好的Secrets对象有两种方式被pod对象使用,其一,在container中的volume对象里以file的形式被使用,其二,在pull images时被kubelet使用。
为了使用Secret对象,pod必须引用这个Secret,同样可以手动或者自动来执行引用操作。
Kubernetes会自动创建包含证书信息的Secret,并且使用它来访问api, Kubernetes也将自动修改pod来使用这个Secret。
自动创建的Secret以及所使用的api证书,可以根据需要disable或者override。如果仅仅需要安全访问apiserver,那么上述的流程是推荐的方式。
很多应用程序的配置需要通过配置文件,命令行参数和环境变量的组合配置来完成。这些配置应该从image内容中解耦,以此来保持容器化应用程序的便携性。ConfigMap API资源提供了将配置数据注入容器的方式,同时保持容器是不知道Kubernetes的。ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
kubernetes通过ConfigMap来实现对容器中应用的配置管理。
从数据角度来看,ConfigMap的类型只是键值组。应用可以从不同角度来配置,所以关于给用户如何存储和使用配置数据,我们需要给他们一些弹性。在一个pod里面使用ConfigMap大致有三种方式:
毋庸置疑,容器是未来的最为重要的配置编排格式之一, 打包应用程序也将会变得更加容易。虽然像Docker这样的工具提供真实的容器,但是也需要其他工具来处理如replication,failover以及API来自动化部署到多个机器。
Service在部署之前存在一个IP地址,但是这个地址只存在于Kubernetes集群之内。这也就意味着service对于网络来说根本不可用!当运行在谷歌GCE上的时候(像我们一样),Kubernetes能够自动配置一个负载均衡器来访问应用程序。如果你不是在谷歌GCE上面的话,你就需要做些额外的工作来使负载均衡运行起来。
将service直接暴露到一个主机端口也可以,这就是经常使用的方式,但这会令很多Kubernetes的优势无法充分发挥。如果依赖主机上的端口,那么当部署多个应用程序的时候,就会陷入端口冲突,这也使得调度集群或者替代主机变得更加困难。
docker run –name myredis -v /Users/xiningwang/nosql/redis/redis-3.2.8/data:/data -p 6379:6379 -d redis redis-server –appendonly yes
Kubernetes将底层的计算资源连接在一起对外体现为一个计算集群,并将资源高度抽象化。部署应用时Kubernetes会以更高效的方式自动的将应用分发到集群内的机器上面,并调度运行。
Kubernetes集群包含两种类型的资源:
当部署应用的时候,我们通知Master节点启动应用容器。然后Master会调度这些应用将它们运行在Node节点上面。Node节点和Master节点通过Master节点暴露的Kubernetes API通信。当然我们也可以直接通过这些API和集群交互。
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
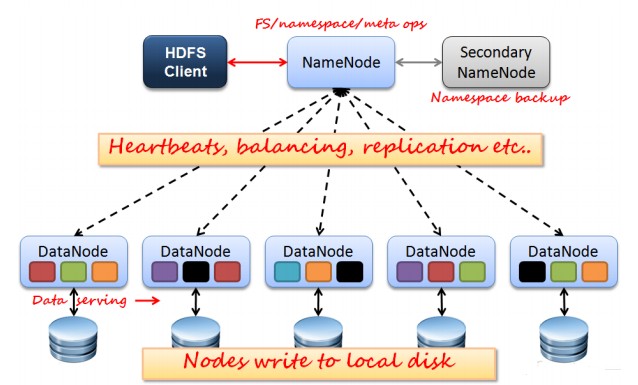
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。