概述
Kafka Streams是一个客户端程序库,用于处理和分析存储在Kafka中的数据,并将得到的数据写回Kafka或发送到外部系统。Kafka Stream基于一个重要的流处理概念。如正确的区分事件时间和处理时间,窗口支持,以及简单而有效的应用程序状态管理,并利用kafka的并行模型来透明的处理相同的应用程序作负载平衡。
- 一个简单的、轻量级的客户端库,可以很容易地嵌入在任何java应用程序与任何现有应用程序封装集成。
- Kafka本身作为内部消息层,没有外部系统的依赖,使用kafka的分区模型水平扩展处理,并同时保证有序。
- 支持本地状态容错,非常快速、高效的状态操作(如join和窗口的聚合)。
- 采用一次一个消息处理以实现低延迟,并支持基于事件时间(even-time)的窗口操作。
- 提供必要的流处理原语(primitive),以及一个 高级别的Steram DSL 和 低级别的Processor API。
以下是几个关键概念的介绍。
Stream处理拓扑
流是Kafka Stream提出的最重要的抽象概念:它表示一个无限的,不断更新的数据集。流是一个有序的,可重放(反复的使用),不可变的容错序列,数据记录的格式是键值对(key-value)。通过Kafka Streams编写一个或多个的计算逻辑的处理器拓扑。其中处理器拓扑是一个由流(边缘)连接的流处理(节点)的图。
流处理器是处理器拓扑中的一个节点;它表示一个处理的步骤,用来转换流中的数据(从拓扑中的上游处理器一次接受一个输入消息,并且随后产生一个或多个输出消息到其下游处理器中)。
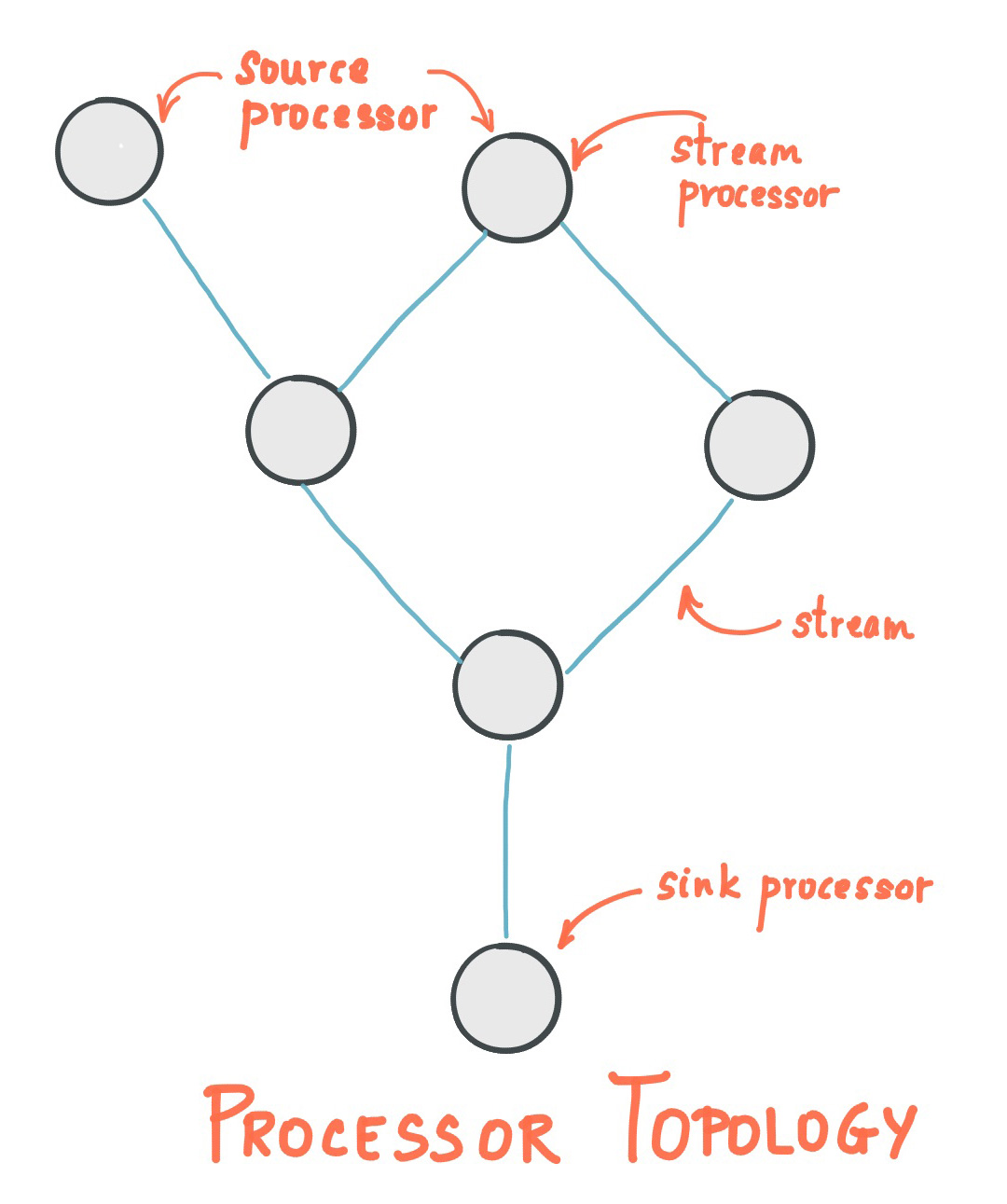
在拓扑中有两个特别的处理器:
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
时间窗口
- 事件时间 - 当一个事件或数据记录发生的时间点,就是最初创建的“源头”。
- 处理时间 - 事件或数据消息发生在流处理应用程序处理的时间点。即,记录已被消费。处理时间可能是毫秒,小时,或天等。比原始事件时间要晚。
- 摄取时间 - 事件或数据记录是Kafka broker存储在topic分区的时间点。与事件时间的差异是,当记录由Kafka broker追加到目标topic时,生成的摄取时间戳,而不是消息创建时间(“源头”)。与处理时间的差异是处理时间是流处理应用处理记录时的时间。比如,如果一个记录从未被处理,那么久没有处理时间,但仍然有摄取时间。
状态存储
Kafka Stream提供了所谓的状态存储,流处理程序可以用来存储和查询数据。在Kafka Stream中的每一个任务嵌入了一个或多个状态存储,可通过API来存储和查询处理所需的数据。状态存储可以是一个持久的key/value存储,内存中的HashMap,或者是其他的数据结构。Kafka Stream提供了本地状态存储的故障容错和自动恢复。